
近期,AI领域迎来了一股新的热潮,DeepSeek公司发布的DeepSeek-V3和R1推理系统引发了广泛关注。该公司在一篇知乎贴文中详细介绍了其系统的架构和性能,揭示了其背后的技术秘密。
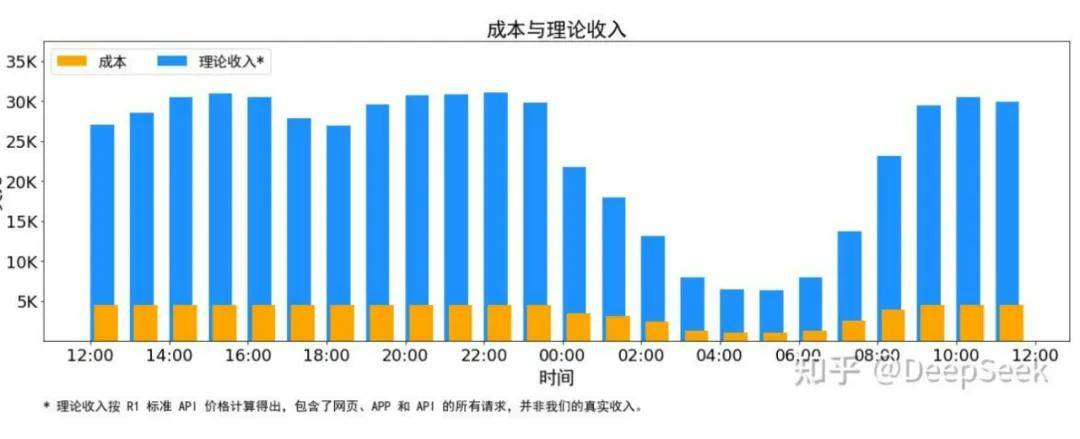
据DeepSeek透露,在过去的24小时(北京时间2025年2月27日12时至2月28日12时)内,其V3和R1推理服务占用的节点总数达到了峰值278个,平均占用节点数为226.75个,每个节点配备8个H800 GPU。若以每小时2美元的GPU租赁成本计算,DeepSeek每天的总成本约为87,072美元。
然而,DeepSeek的收益远超过这一成本。根据DeepSeek R1的定价策略——缓存命中每百万输入tokens收费0.14美元,缓存未命中则收费0.55美元,每百万输出tokens收费2.19美元——DeepSeek理论上每天的总收入可达到562,027美元,成本利润率高达545%,即每天的理论利润约为474,955美元。

尽管实际收入并未达到这一理论值,因为V3的定价更低,且收费服务仅占一部分,夜间还有折扣,但DeepSeek的盈利能力依然令人瞩目。其独特的模型架构和推理系统优化策略,使得其能够在保证高效推理的同时,降低成本,提高利润。
DeepSeek的推理系统采用了大规模跨节点专家并行(Expert Parallelism/EP)策略,这一策略使得batch size大大增加,提高了GPU矩阵乘法的效率,从而提高了吞吐。同时,EP使得专家分散在不同的GPU上,降低了延迟。然而,EP也增加了系统的复杂性,需要设计合适的计算流程来优化吞吐,以及进行负载均衡。
硅基流动创始人、CEO袁进辉对DeepSeek的架构表示赞赏,认为其与其他主流模型架构存在显著差异,由大量小Expert组成,导致其他针对主流模型结构开发的系统不再有效。他指出,DeepSeek团队的第一性原理思考方式和强悍的意志使其能够克服巨大的工程挑战,最终取得成功。
DeepSeek的火爆也引发了市场的广泛关注。英伟达等公司的股价在DeepSeek发布这一系列成果后受到了影响。有行业人士评论称,DeepSeek的这一波操作可能再次对英伟达等公司的股价构成压力。
DeepSeek在知乎贴文中还详细介绍了其推理系统的优化目标和具体实现方法。其目标是实现更大的吞吐和更低的延迟,通过EP策略、计算通信重叠以及负载均衡等技术手段,DeepSeek成功地提高了系统的性能。
在统计时段内,DeepSeek V3和R1的输入token总数为608B,其中56.3%命中了KVCache硬盘缓存。输出token总数为168B,平均输出速率为20~22 tps。平均每台H800的吞吐量为:对于prefill任务,输入吞吐约73.7k tokens/s(含缓存命中);对于decode任务,输出吞吐约14.8k tokens/s。这些数据显示出DeepSeek推理系统的高效性能。
DeepSeek的成功不仅体现在其技术上,更体现在其对市场的影响上。其高性能预算产品质疑了未来在英伟达芯片和开发上花费数千亿美元的必要性,挑战了市场对AI、估值和高支出的叙述。


